Arquitecturas Hiperconvergentes
Infraestructura Definida por Software

Arquitectura I/O
En el núcleo de una plataforma hiperconvergente de alto rendimiento se encuentra la CVM (Controller Virtual Machine). Esta entidad se ejecuta de manera dedicada en cada nodo del clúster y toma control directo (PCIe Pass-through) de las controladoras de almacenamiento locales.
- Localidad de Datos (Data Locality): La HCI garantiza que los datos en caliente de una máquina virtual (VM) residan en el almacenamiento del mismo nodo físico que la ejecuta. Esto significa que las peticiones de lectura no viajan por la red, eliminando latencia y cuellos de botella del tejido de red (Fabric).
- Escrituras Sincrónicas: Para garantizar la tolerancia a fallos, cada bloque de datos escrito por una VM se guarda localmente y se replica sincrónicamente a través del bus de red (10/25/100 GbE) hacia las CVM de otros nodos antes de confirmarle el Acknowledge (ACK) al sistema operativo invitado.
- Balanceo Automático (Auto-Tiering): Las CVM detectan patrones térmicos en los datos (Hot/Cold Data). Los metadatos y datos activos se mantienen en caché NVMe/SSD, mientras que los bloques fríos se mueven a discos de capacidad, optimizando la relación IOPS/GB sin intervención humana.
⬛
Consolidación y SDS
El almacenamiento se presenta al hipervisor mediante protocolos estándar (NFS, iSCSI, SMB) a través de un bus lógico virtual. Al abstraer el plano de control del plano de datos, eliminamos las LUNs rígidas, permitiendo operar a nivel de granularidad de VM (vDisk).
📈
Escalamiento Predictivo
Arquitectura Scale-Out pura. Al añadir un nodo físico, un algoritmo de hash consistente se encarga de redistribuir los bloques de metadatos en segundo plano. Esto asegura que la capacidad de CPU, RAM e IOPS aumenten de manera completamente lineal.
⚙️
Orquestación API-First
Toda acción en el clúster HCI está modelada inicialmente como una llamada API REST. Esto facilita la integración total con herramientas de Infraestructura como Código (IaC) como Terraform o Ansible, automatizando pipelines de CI/CD corporativos.
🔄
Consenso y Resiliencia
La integridad de los metadatos se mantiene mediante algoritmos de consenso distribuido (tipo Paxos/Cassandra). El sistema soporta configuraciones Block Awareness, sobreviviendo a la caída no solo de un disco o nodo, sino de un rack completo.
📉
Reducción de Datos en Línea
Implementación de técnicas de compresión algorítmica (LZ4), deduplicación por hash y Erasure Coding (EC). Estas tecnologías minimizan el espacio requerido en unidades Flash sin degradar el rendimiento crítico de lectura/escritura de las bases de datos.
🛡️
Microsegmentación (SDN)
Integración nativa de Software-Defined Networking. Los firewalls distribuidos operan a nivel de la interfaz de red virtual (vNIC). Cada VM tiene su propio perímetro lógico L4-L7, confinando infecciones y evitando movimientos laterales en el clúster.
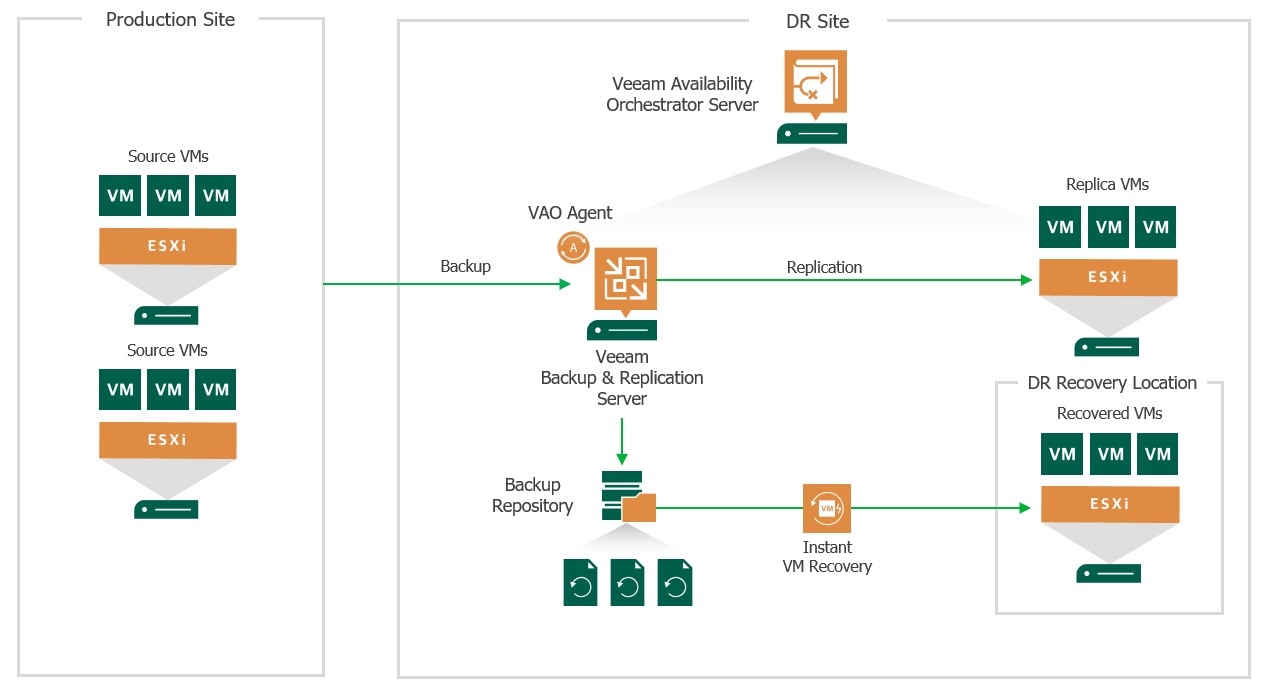
Continuidad Operativa
La protección de la información corporativa no debe depender de costosas herramientas de terceros. Las arquitecturas hiperconvergentes integran flujos de backup y Disaster Recovery de forma nativa a nivel del hipervisor y del bloque de almacenamiento.
- Snapshots Redirect-on-Write (RoW): A diferencia de las copias tradicionales Copy-on-Write (CoW), la arquitectura RoW no penaliza el rendimiento I/O (Input/Output). Los metadatos simplemente redirigen los punteros hacia nuevos bloques, permitiendo generar miles de snapshots instantáneos sin impactar el rendimiento de la VM activa.
- Topologías de Replicación: Configuramos políticas asíncronas para cumplir con objetivos de punto de recuperación (RPO) de minutos en sitios remotos. Para entornos de misión ultra-crítica, implementamos Metro Availability (Replicación Síncrona), estirando el clúster a través de centros de datos separados geográficamente para garantizar un RPO igual a cero (0).
- Recuperación Granular: El sistema de archivos distribuido permite aislar y restaurar archivos individuales o bases de datos desde un snapshot remoto sin necesidad de restaurar todo el VHD (Virtual Hard Disk) asociado a la máquina virtual.